sklearn数据预处理和特征工程

sklearn数据预处理和特征工程
数据预处理
数据的无量纲化
一般来说,当我们将数据导入模型的时候,无量纲化的可以帮我们去除量纲对模型的影响(决策树和随机森林不需要这样做,它可以处理大多数数据)
一般来说线性的无量纲化包括去中心化和缩放处理,中心化就是将原本的数据通过加减一个固定值使他进行平移,缩放就是对数据乘除一个固定值使其处于某一种范围之中,例如取对数。
归一化
归一化处理,可以将数据缩放到0-1之间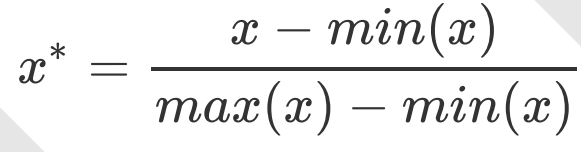
上面这个肯定会很眼熟,代码实现还是老三样
- 实例化
- 用
fit()处理数据 - 导出结果或者也可以一步到位
1
2
3
4
5
6
7from sklearn.preprocessing import MinMaxScaler
import pandas as pd
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
scaler = MinMaxScaler() #实例化
scaler = scaler.fit(data) #fit,在这里本质是生成min(x)和max(x)
result = scaler.transform(data) #导出结果或者你也可以将数据归一化到其他范围1
result_ = scaler.fit_transform(data)
1
2
3scaler = MinMaxScaler(feature_range=
[5,10])
result = scaler.fit_transform(data)标准化
标准化处理可以将数据缩放到-1-1之间
代码为
1 | from sklearn.preprocessing import StandardScaler |
标准化和归一化如何选择
在大多数机器学习里都是选择标准化来进行特征缩放的。
而归一化对于异常值较为敏感,优点是便于计算,可以用在图像处理等方面。
填补缺失值
首先导入菜菜给的泰坦尼克号数据
1 | import pandas as pd |

1 | Age = data.loc[: ,"Age"].values.reshape(-1,1) |
data是pandas的DataFrame结构data.loc[: ,"Age"]是Age所在行,是一个字典形式的量,即索引对应年龄data.loc[: ,"Age"].values取出了字典中所有值,即取出所有年龄,是一个一维数组data.loc[: ,"Age"].values.reshape(-1,1)将其转化二维列向量,reshape(a,b)指的是转化为a行b列的二维向量,其中-1代表自动计算。
依然是
- 实例化
SimpleImputer() result = fit_transform(yourdata)data.loc[:"Age"] = result1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
from sklearn.impute import SimpleImputer
imp_mean = SimpleImputer() #实例化,默认均值填补
imp_median = SimpleImputer(strategy="median") #用中位数填补
imp_0 = SimpleImputer(strategy="constant",fill_value=0) #用0补
imp_mean = imp_mean.fit_transform(Age)
imp_median = imp_median.fit_transform(Age)
imp_0 = imp_0.fit_transform(Age)
#在这里我们使用中位数填补Age
data.loc[:,"Age"] = imp_median
data.info()
#使用众数填补Embarked
Embarked = data.loc[:,"Embarked"].values.reshape(-1,1)
imp_mode = SimpleImputer(strategy ="most_frequent")
data.loc[:,"Embarked"] = imp_mode.fit_transform(Embarked)
data.info()data.loc[:,"Age"] = imp_median这里是可以直接赋值的,虽然他两类型不同,一个是字典一个是二维数组
也可以直接用pands和numpy填补也可以直接将缺失的数据丢掉1
data.loc[:,"Age"] = data.loc[:,"Age"].fillna(data.loc[:,"Age"].median())
1
2data.dropna(axis=
0,inplace=True)axis = 0代表对行操作,inplace = True代表直接对原数据替换编码
其实就是将文字型变量转化为数值型
依然是三步:- 实例化
LabelEncoder() le.fit_transform(data.iloc[:,2])data.iloc[:,2] = result
1 | from sklearn.preprocessing import LabelEncoder |
二值化和分段
二值化
例如我们可以将上述数据二值化,大于30岁的赋值为1,小于30岁的赋值为0
嘿嘿,老三样,只是这次又得转为二维数组
1 | from sklearn.preprocessing import Binarizer |
分段
这次KBinsDiscretizer()里面有几个重要参数
- n_bins是分的类的数量
- encode是编码方式,’ordinary’,指的是返回一个整数,如分成三个类返回0,1,2构成的数列
- strategy有三种”uniform”是等宽分类,用最大值与最小值之差除与类的数量作为每个类的宽度,”quantile”是将每个类中的样本数分的都相同,“kmeans”是用kmeans聚类的方法来分类
1
2
3
4from sklearn.preprocessing import KBinsDiscretizer
X = data.iloc[:,0].values.reshape(-1,1)
est = KBinsDiscretizer(n_bins=3, encode='ordinal', strategy='uniform')
est.fit_transform(X)
- Post title:sklearn数据预处理和特征工程
- Post author:newsun-boki
- Create time:2021-11-02 01:09:17
- Post link:https://github.com/newsun-boki2021/11/02/python-data-process/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.