
强化学习阅读笔记
以前总是对强化学习一窍不通,但看到各种演示视频总觉得非常有趣,于是花3块钱在淘宝上搞了本电子书开始了我的强化学习之旅。为了防止我学完之后什么也不记得,特此写下阅读笔记

I. 导论
1.1 强化学习
强化学习的定义:学习做什么能使数值化的收益信号最大。学习者并不会被告知采取什么动作,而是通过自己的尝试去发现什么动作会产生最大的收益。
强化学习不是有监督学习,也不是无监督学习,而是独立的。其与无监督学习的区别是:
- 无监督学习是寻找未标注数据的隐含结构的过程。
- 强化学习的目标是最大化收益信号。
强化学习的两个关键特征:
- 强化学习需要在试探与开发之间权衡。虽然强化学习智能体一定更喜欢过去有效产生收益的动作,但需要尝试从未选择过的动作,即走出“舒适圈”。
- 强化学习需要明确考虑目标导向的智能体与不确定环境的交互这一整体问题,而不是一些孤立的子问题。注意强化学习是完整的交互的。
强化学习与心理学和神经科学之间关系紧密,是和人类或动物最接近的一种学习方式,受到生物学习系统的影响。
1.2 示例
- alphaGo围棋大师
- 一只羚羊幼崽出生后尝试着站起来
- 准备早餐。你可知道准备一个早餐是多么复杂的一个流程。走进橱柜,打开橱柜等等等等,对于现在的机器人来说几乎是不可能的事情。
1.3 强化学习要素
- 策略:学习智能体在特定时间的行为方式。环境状态到动作的映射。
- 收益信号:强化学习中问题的目标,决定了什么是好什么是坏。类似痛苦或者愉悦,是一种短期的收益。
- 价值函数:从长远的角度看什么是好的。一个状态的价值是一个智能体从这个状态开始,对将来累计的总收益的期望
收益信号和价值函数就像短期的愉悦与长远的快乐。价值是我们最为关心的,我们选择动作是基于最高价值。但确定价值比确定收益难的多。就像你现在知道学习是痛苦的(收益低),但你不知道这样学下去未来会怎么样(价值难以确定)。收益基本是由环境直接给予的,而价值必须综合评估,根据智能体在整个过程中的收益序列重新评估。价值评估方法才是整个强化学习的关键。
- 最后是对环境建立的模型。这个模型是用于预测的,是我们最终得出来的结果。
1.4 局限性和适用范围
状态是强化学习的核心,这种状态是策略和价值函数的输入,又是模型的输入与输出。
解决强化学习问题的方法一定不只强化学习。比如可以通过遗传算法,模拟退火等进化算法来解决。这些方法不计算价值函数,而是选择收益最多的策略及其变种来产生下一代。对于策略空间较小的问题,这些算法是有效的。
强化学习是在于环境互动中不断学习的一类算法。
1.5 强化学习的早期历史
强化学习的历史发展中有两条主线,在现代强化学习之前他们是相互独立的:
- 源于动物学习心理学的试错法
- 最优控制问题以及使用价值函数和动态规划的解决方案
还有时序差分的研究
第一部分 表格型求解方法
简单强化学习问题,状态和动作空间小到可以用数组或表格形式来表示价值函数。一般来说可以找到精确解。
II. 多臂赌博机
- 评估性反馈:依赖于当前采取的动作,即采取不同的动作会得到不同的反馈(强化学习)
- 指导性反馈:不依赖于当前的动作,即采取不同的动作也会得到相同的反馈(其他机器学习)
2.1 一个k臂赌博机问题
重复的在k个选项或者动作中做出选择,每次做出选择都会获得一定数值的收益,收益是由选择的动作决定的平稳的概率分布。目标是:某一短时间内最大化总收益的期望。比如1000次选择内。
k个动作每一个在选择后都有一个期望或者平均收益称为这个动作的价值。在时刻
一定要理解:价值是收益的期望。事实上我们并不能准确的知道价值,所以智能有一个对
如果一直对某个价值进行估计,那么在任一时刻至少有一个动作的估计值会是最高的,将这些对应的最高估计价值对应的动作称为贪心的动作。如果你选择了这些贪心的动作,则称作开发,如果选择了其他看起来没那么好的动作,那就是试探。开发是贪心的选择短期收益最大的,而试探是在放弃短期收益,尝试有没有更好的选项。由于每一次选择,开发和试探不可能同时进行,这就是开发和试探的冲突。
开发和试探的平衡是强化学习中的一个重要问题。
2.2 动作-价值方法
接下来讲的就是怎么估计动作对应的价值,计算
然后接下来用估计出的价值
$$
A_t = \mathop{\arg\max}{a}Q_t(a)
$$
这种方法根本不花时间去选择那些看起来劣质的动作,但是有的时候估计值也不一定对。因为估计的时间是有限的。此时可以用另一种近乎贪心的算法,比如有时候会以一个很小的概率
2.3 10臂测试平台
我们来看一个实际案例,10臂,意为着有10种动作,每种动作对应着不同收益的概率分布如下图。
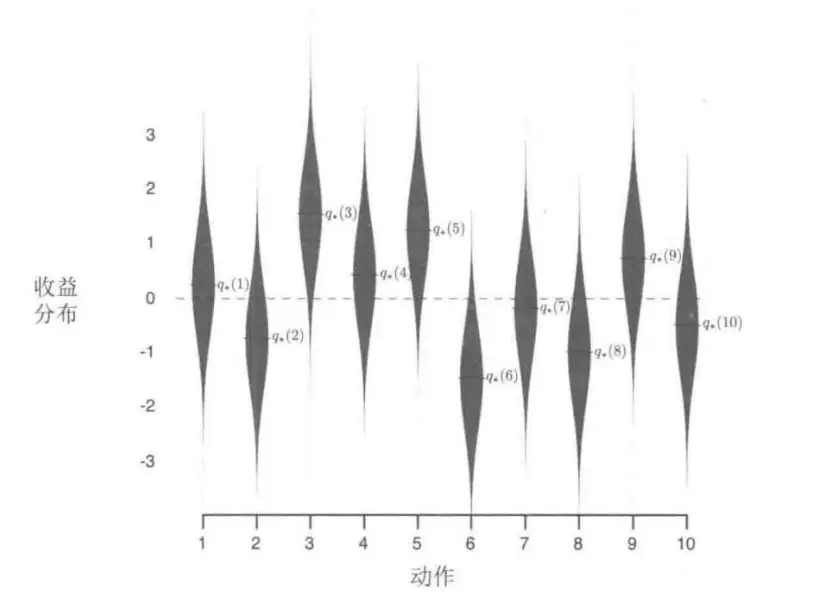
当然实际上我们应该是不知道上述分布的,而是我们试探来尽量估计。比如首先来个1000次来估计其每个动作的价值

可以看出纯粹贪心的算法长远上来看效果是没有
2.4 增量式实现
事实上对于某一个动作,我们令
但我们总不可能每进行一次动作都去算一下这个式子吧,那样只会随着次数的增多越来越麻烦,显然我们是能够仅仅根据
推导这里就不列出来了,因为非常简单,有没有发现这种形式很眼熟:
这里的步长就是

2.5 跟踪一个非平稳的问题
前面我们跟踪的都是一个平稳的问题,即动作对应的真实价值是不随着时间变化的。但强化学习面对的问题往往都是非平稳的问题,即动作的真实价值是随着时间变化的,也就是说以前估计值过一段时间就不能用了,我们必须时刻保持估计值最新。按之前的写法:
我们显然可以发现越往后,后面的实际收益对估计值影响越小(因为
这个里面
2.6 乐观初始值
乐观初始值体现在对初始值的改变。以前都是将初始估计值设置为0,现在我给它全部+5。与原来初始估计值设置为0相比,给它+5意味着鼓励动作-价值方法去试探,因为他会发现无论选哪一个都达不到5。当然随着时间不断增加,所谓智能体就会发现实际上哪一个动作的价值都不是5,但由于它前面已经试探了够多,保证他有充足的时间去估计动作对应的价值

当然,这种方法对于非平稳情况几乎没用,因为改变初始值只能够影响一开始的状况,但显然之后价值不断变化初始值也不能产生任何影响。
2.7 基于置信度上界的动作选择
之前的
这种方法的主要思想是,对于一种动作,我选择的次数越多,我就越不想选他,选一些没选过的。具体方程就是
其中
这种方法在10臂测试平台上效果确实是比
2.10 本章小结
为什么直接跳到2.10呢,因为前面的梯度赌博机和上下文关联算法懒得看了。这里总结一下,主要就是
-贪心方法。一小段时间内进行动作的随机选择。 - UCB方法。采用确定的动作选择,但趋向于选择较少使用的动作.
- 梯度赌博机算法。不估计动作价值,而是利用偏好函数,使用softmax分布来以一种分级的概率的方法选择更好的动作。
至于哪个方法最好,只能说在10臂测试平台上是UCB最好吧,但不同的问题也不一样。这些方法看起来简单,但事实上都是强化学习中最基本的思想。
III. 有限马尔科夫决策过程
前面的多臂赌博机已经体现了一些强化学习中的基本思想如:
- 价值与收益:在多臂赌博机中价值是收益持续下去的期望,而对于价值的估计就是整个强化学习的关键,这个思想将贯穿整个强化学习始终。
- 策略:即选择动作的方法。诸如
-贪心方法或者UCB方法,这些方法的思想也会在后续用到。
上述三点实际上已经是强化学习的核心,接下来就是搭建一个过程,我们称之为有限马尔可夫决策过程(有限MDP),以及引入一个名叫状态的概念。如果你学过数电,你可以把这种过程和有限状态机联系起来,因为确实很像,特别是画出状态转移图之后。之前的多臂赌博机并没有这种状态的概念,但在强化学习中状态是不可或缺的,对于不同的状态需要选择不同的动作。
3.1智能体-环境交互接口
- 智能体。就是决策者本身,可以是指动物的大脑,或者说我们的计算终端(PC之类的)。
- 环境。这里的环境其实就是除了智能体一切外界的东西,不同场景下环境是不同的,比如说一个机器人,它的手臂等也是属于环境,因为它是驱动电机来运动。
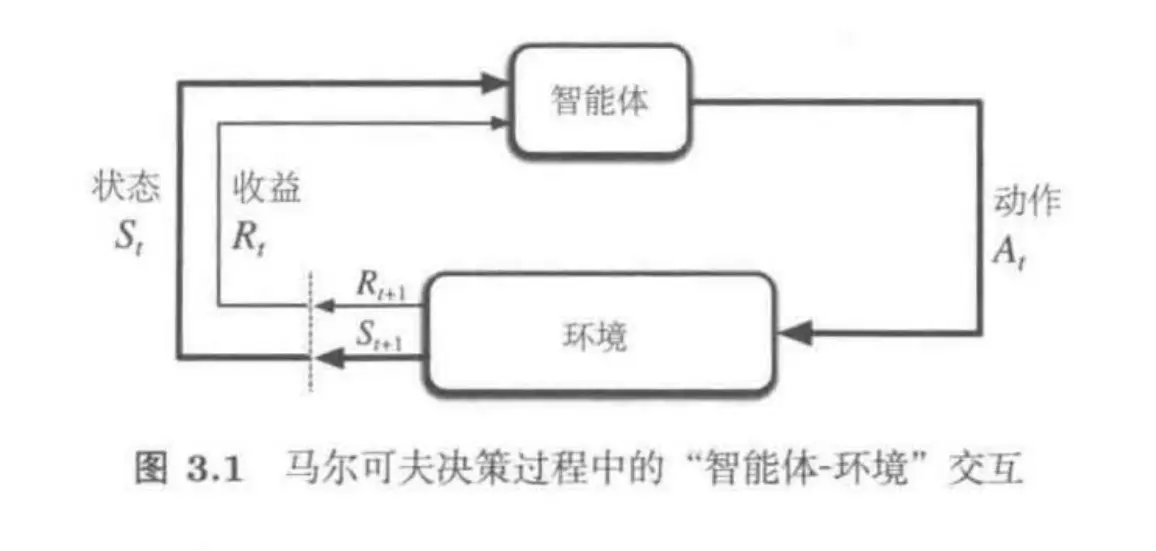
上面这幅图就是整个有限马尔科夫决策过程的整体流程,上面这个循环,实际上可以换一种形式表示:
其中
对于有限MDP, 这些状态动作和收益是一个有限的集合,于是收益和状态仅仅依赖于前继状态和动作,与更早的状态和动作无关,且都具有离散的概率分布。也就是说当某一个状态下做某一个动作会产生多种可能的下一个不同的状态和收益,这些可能服从一个概率分布。
上面的公式是一个定义,在马尔科夫决策中,上述公式刻画了环境的动态特性,对于复杂的环境概率分布会更加复杂。状态必须包括智能体和环境交互方方面面的信息,这些信息会对未来产生一定的影响。这样的状态就具有了马尔科夫性。
那么现在我们可以用这些东西算一些东西了,比如状态转移的概率:
上面的公式认真看一看就懂了,我们还可以定义期望收益,即某种状态下做某种动作的收益的期望。注意期望收益还是收益,不要和价值混为一谈。
当然还有一种期望收益是某种状态下做出某种动作后转移到另一状态时产生的收益。
MDP框架非常灵活,适用面也很广。首先,时间步长可以自己随便定,可以是真实的时间间隔,也可以是每次决策的间隔。动作同样也可以是低级的控制,例如机械臂的电机电压,也可以是是一个高级的决策,比如早餐吃什么。当然强化学习的适用面也非常广。总之不要忘记马尔科夫决策的三个关键,行动,状态以及收益。
下面有个扫地机器人充电,等待还是搜索的案例。s代表电量,a代表充电搜索还是等待,r代表收益。注意看r中有一个-3项,因为那是低电量情况下还强行搜索,只能被救援,然后电量就又高了。剩下的相信聪明的你都能看懂,是不是很有数电的感觉。

3.2 目标和收益
在强化学习中,智能体的目标被形式化表征为收益,通过环境传给智能体。在每一个时刻,收益都是一个单一标量数值。智能体的目标就是最大化其收到的总收益,类似我们前面所说的价值。也就是说最大化的不是当前收益,而是累积收益,学术一点说,就是最大化智能体接受到标量信号累积和的概率期望值。举个例子:
- 机器人学走路:每个时刻都提供与机器人向前运动成比例的收益。
- 机器人走迷宫:成功逃脱前每一个时刻的收益都是-1,鼓励机器人快逃。
- 机器人捡易拉罐:捡到一个罐子收益+1,撞到东西给它负收益。
- 机器人下棋:赢了就收益为+1,失败就为-1。注意这里给收益的条件是要胜利,而不是吃掉对面的棋子,否则可能会出现机器人光顾着吃棋子不想赢的情况。
3.3 回报和分幕
之前为我们说机器人的目标是最大限度的提高长期收益,我们把这个长期收益称为回报,在最简单的情况下,回报是未来收益的和:
其中T是最终时刻,很多情况下都会有最终时刻这种概念(一盘游戏,一次走迷宫),智能体和环境的交互能够被自然的分成一系列子序列,每个子序列都存在最终时刻。我们把每个子序列称为幕(episodes)或者说试验(trials)。这是一个重复性的过程,每一幕都以一种状态结束称为终结状态,随后会从某个标准的起始状态或起始状态的分布中某个状态样本开始。结束的方式不同并不影响开始的状态。有这种重复特性的任务称为分幕式任务。
另一种情况,当是一个长期持续性的任务时,是无法分幕的,这种我们称为持续性任务。因为这种时候
其中
这样看起来是不是未来值就开始变成一个有限值了呢,因为折扣率
- Post title:强化学习笔记
- Post author:newsun-boki
- Create time:2022-03-24 02:56:32
- Post link:https://github.com/newsun-boki2022/03/24/rl-note/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.